Enterprise AI
Agentic AI Document Review
60–80% reduction in manual document review effort — Fortune 500's first production agentic AI workflow.
Customer
Fortune 500 Industrial Manufacturing Enterprise (PPD Division)
Timeline
2025–2026 · Current
Status
Shipped — running in production
Capability
Stack
Outcome
Customer Context
Who they are and what world they live in
A Fortune 500 industrial manufacturer's product documentation division reviews hundreds of high-stakes customer-facing documents per month — product specifications, compliance reports, technical manuals — against a Style Guide and a Quality Review Rubric. The reviewers are domain experts, not engineers. They were doing this entirely manually: open the document, read against the rubric, flag issues, repeat for 200+ pages. The inconsistency across reviewers created audit-grade rework loops. Leadership knew they had a problem. Nobody had shipped a fix.
The Problem
The fuzzy ask, translated
The ask was vague: 'can AI help with document review?' The real problem had three parts: (1) reviewers were burning hours per week on mechanical, repeatable policy checks that didn't require their domain expertise; (2) reviewer inconsistency meant the same document could get different results on different days; (3) findings had to be fully auditable — every flag traceable to a page number and a specific standards reference — because these documents affected customer experience and had compliance implications.
The Constraints
Time · Budget · Regulatory · Technical · Organizational
Enterprise security posture: SSE-KMS encryption at rest, IAM least-privilege, no external data transmission — document content cannot leave the AWS account boundary
Full auditability: every finding must be traceable to page number, standard type (Style Guide vs Rubric), and a specific excerpt — no black-box output
Existing Kendra GenAI index: the standards knowledge base already existed and was managed externally — read-only, no modification
No database: org constraint — S3 is the system of record for all pipeline artifacts
200+ page PDFs: large documents requiring chunked processing with guaranteed coverage
Deterministic, reproducible output: temperature=0.0, strict JSON schema — same document must produce the same findings across runs
Volunteer-friendly failure handling: a FAILED manifest must exist even on terminal failure so operations teams can triage without digging through logs
Architecture
System design
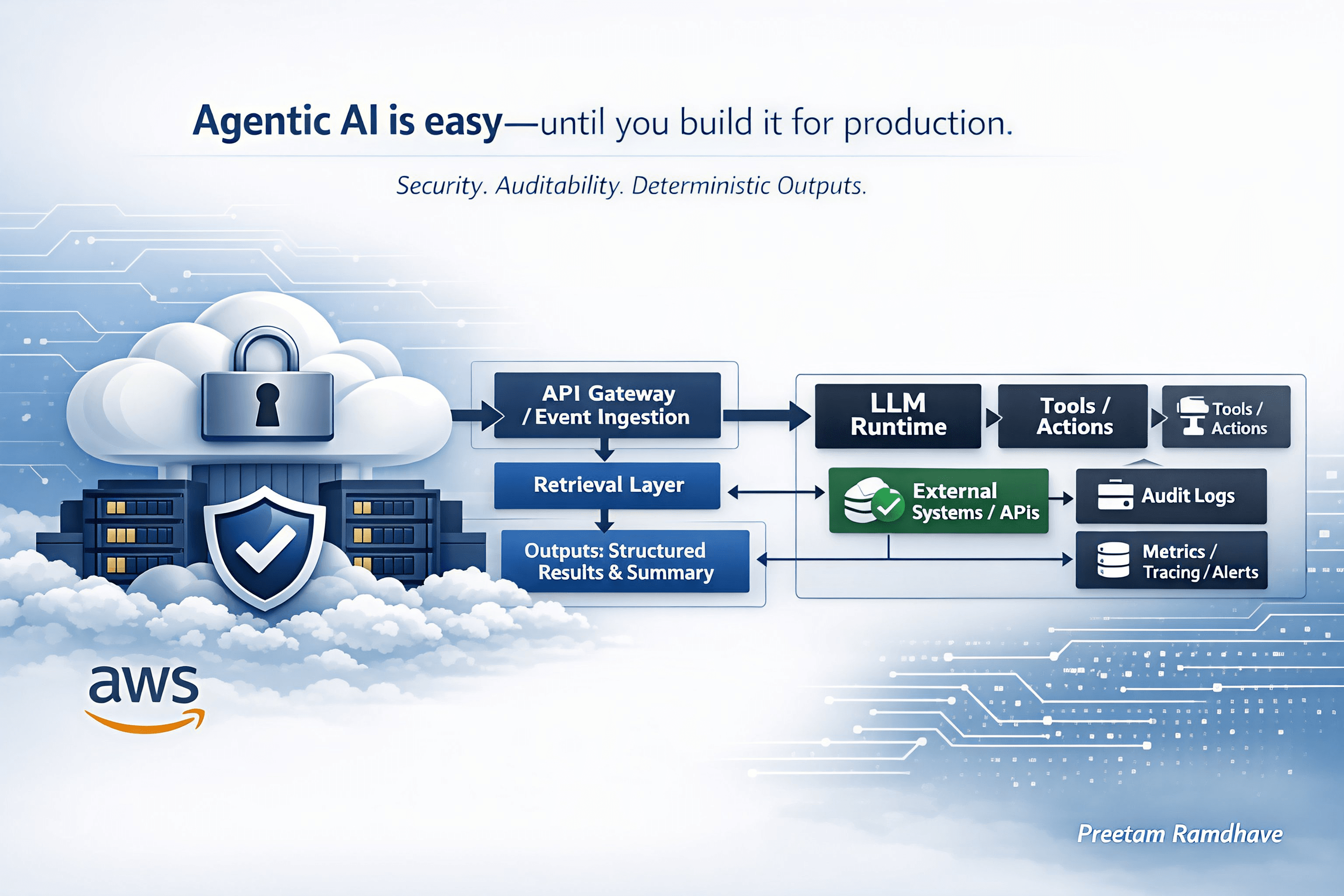
Architecture Decisions
What I chose. What I rejected. Why.
Orchestration engine
Chosen
AWS Step Functions Standard workflow
Rejected
Step Functions Express / direct Lambda chain
Why
Standard workflows provide durable execution history — every state transition is logged and queryable. For a compliance-grade system, the audit trail of the orchestration layer matters as much as the output.
Processing stages
Chosen
5 modular Lambda functions (pdf_extract → chunk_plan → kendra_retrieve → bedrock_review → aggregate_render)
Rejected
Monolithic Lambda
Why
Each stage is independently testable, deployable, and reusable. pdf_extract can be tested against a corpus of PDFs without touching the LLM layer. bedrock_review can be tested with canned Kendra results. Decomposition was the only path to reliable production.
State persistence
Chosen
S3 with deterministic key layout: jobs/{jobId}/pages/{NNNN}.json, findings/chunk-*.json, outputs/report.csv, manifest.json
Rejected
DynamoDB or RDS for intermediate state
Why
S3 as system of record eliminates an entire class of operational complexity. Any job can be replayed from any stage by re-running from the relevant artifact. Debugging means reading a file, not querying a database under pressure.
LLM model selection
Chosen
Claude 3.5 Haiku via Amazon Bedrock at temperature=0.0
Rejected
Claude 3.5 Sonnet
Why
Haiku at temp=0.0 delivered equivalent compliance-review quality at significantly lower cost per chunk, with more predictable latency for large parallel Map states. Deterministic temperature was non-negotiable for reproducible audit output.
Output validation
Chosen
Strict JSON schema enforcement + one repair attempt with a dedicated repair prompt
Rejected
Retry with identical prompt / accept partial output
Why
A single repair attempt with a different prompt surface catches most formatting failures without creating infinite retry loops. If both attempts fail, the chunk is marked failed and the coverage gate catches it at aggregation — no silent partial reports.
The Hard Problem
The one thing that almost broke the deployment
Claude was producing structurally invalid JSON on ambiguous policy sections — not hallucinating content, but hallucinating structure. When a rubric item was genuinely unclear, the model would add prose commentary outside the JSON envelope. The initial design had no way to distinguish 'valid finding' from 'model commentary masquerading as JSON'. The coverage gate didn't exist yet, so partial chunk outputs were silently passing through to the final report.
The Fix
Two changes. First: strict JSON schema validation on every bedrock_review output, with exactly one repair call using a dedicated repair prompt that explicitly re-states the schema contract and shows the malformed output back to the model. Second: coverage gating at aggregate_render — the stage reads the chunk plan and verifies every planned chunk produced a findings artifact before rendering the CSV. A missing artifact is a terminal failure, not a warning. A FAILED manifest is written before the workflow terminates so operations always has a durable failure record.
Production Reality
What I had to fix in week 2
The coverage gate wasn't in the initial design. It was added after a partial report completed without flagging missing chunks — the report looked complete but wasn't. The S3 deterministic key layout saved the recovery: we could identify exactly which chunk artifacts were missing by diffing the plan.json against the findings/ prefix. That experience hardened the rule: the plan is the contract; aggregation validates against it before producing any output.
Lessons Carried Forward
What this taught me that I apply to every deployment
Coverage gates prevent the silent partial failure mode — if the plan says 50 chunks, the aggregator must see 50 findings artifacts or refuse to produce output
temperature=0.0 + strict JSON schema enforcement is the minimum viable setup for auditable LLM output in an enterprise context
S3 deterministic key layout beats any database for pipeline state when your primary operations need are replay, audit, and debugging
Decompose Lambda stages early — every boundary is a test seam; monolithic pipelines become untestable under production pressure
Write the failure manifest before the success path — operations teams will need it more than the happy path
The modular Lambda patterns from this deployment are now reference architecture across the division — generalization is a deliverable, not a bonus
Related Deployments